How ChatGPT Landed Us in Hot Water on Hacker News - Was It Worth It?
In early 2023, we embarked on a mission to create a central, free dataset of companies that could serve as a valuable resource for startups. This dataset, comprising approximately 15 million company records, included essential attributes like name, industry, location, and size. With our experience in the data industry, we were confident that this would become one of the largest, if not the largest, free company datasets available.
To announce our new dataset, and hopefully create a viral post on Hacker News, we turned to ChatGPT. Our strategy was twofold: first, to provide a base dataset for the community to build upon, and second, to use the free dataset as a lead generation tool for our premium, paid dataset.
ChatGPT suggested an article with the provocative title "Introducing the World's Largest Open Source Dataset." Initially, we were hesitant about such a bold claim, so we engaged ChatGPT in a dialogue to clarify our approach.
Ultimately, ChatGPT advised that while the title would likely generate controversy, traffic it would drive would be worth it. To help offset our concerns, ChatGPT also recommended adding a "playful message" as a disclaimer:
Disclaimer: Okay, we have to admit, we didn't exactly comb through every dataset out there to verify that ours is the world's largest, but we did our research, and we're pretty sure it might be. Whether or not that's true, we believe this dataset is a robust and invaluable resource for anyone interested in company data.
We also sought insight into why this title and content would resonate with the Hacker News community, and ChatGPT provided convincing reasons:
- Being a unique and valuable dataset.
- Being open source.
- Bridging the worlds of business and technology.
True to ChatGPT's predictions, our Hacker News post quickly gained traction and reached the #1 spot.
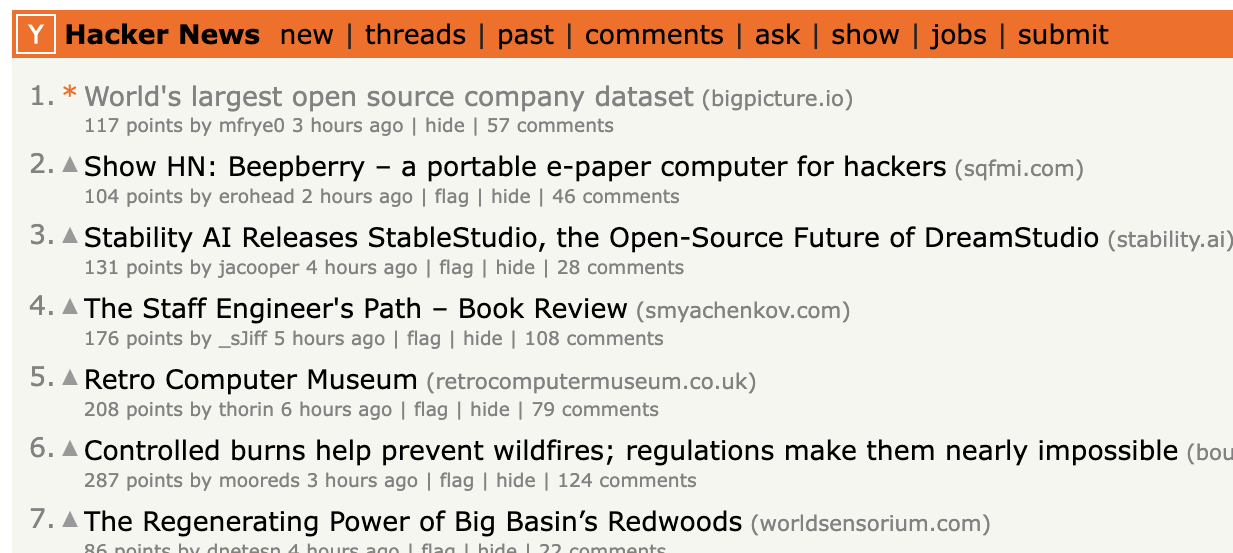
We were thrilled with the influx of traffic, comments, and sign-ups, but the experience came with its share of criticism.
The main points of criticism centered around:
- Lack of an open-source license.
- The controversial title claiming the dataset as the "world's largest."
- Requiring sign-ups to access the dataset.
Addressing these concerns:
Open Source License: We confess that we were so focused on sharing the data that we overlooked the essential aspect of open-sourcing a dataset. After some research, we decided to adopt the Open Data Commons Attribution License and have added license information to our dataset documentation and terms of service.
The Title: As we anticipated, the title was met with skepticism. In response, the moderator "dang" eventually changed it to a less sensational title: "A raw dump of companies from all over the world by LinkedIn handle." We remain open to feedback and invite anyone to inform us if they come across a larger, more comprehensive, free company dataset.
Requiring sign-ups: We understand that asking people to sign up for a free dataset may not be ideal. As a bootstrapped company, we lack the financial resources of larger organizations. To continue developing and offering a free dataset, we need to generate paying customers for a sustainable business.
What did surprise us, however, was the sheer amount of negativity. Admittedly, we made a mistake regarding the open-source issue, and some individuals called us out for being "amateur."

One individual took it to another level by stating he wanted to "waste your bandwidth" and proceeded to download the 1GB free dataset repeatedly - essentially a DDoS attack. He racked up a sizable AWS bill before we caught and stopped it.
So, was it worth it?
The age-old saying claims "there's no such thing as bad publicity." In our case, despite receiving criticism from the Hacker News community, it ultimately proved to be a successful venture. It drove a significant volume of traffic to our site and attracted the interest of numerous companies keen on our premium datasets.
Since the dataset's launch, we've formed partnerships with a substantial percentage of Y Combinator (YC) companies and even OpenAI, proving that sometimes, bold moves can lead to big opportunities.
We have released two updates to the dataset for Q3 and Q4, pushing our record count to over 17 million. We are dedicated to making ongoing improvements and addressing the feedback we've received to continue serving the startup community and beyond.
We welcome your thoughts and contributions. Your feedback will help us improve our dataset and make it an even more valuable resource for the startup community. If you're interested in collaborating or have suggestions, please reach out to us; we value your insights.